
虹莹发来《威敏神学》的修订版,按照“橡树”的体例进行了修正。
“橡树”的要求里有一条和我从前所想的不同,就是所有圣经书卷都需得加上书名号。我对虹莹说,不要自己做了,弄一个全局搜索替换,遍历66卷就解决问题。但虹莹还是自己手工做了一遍。
Anyway,我只好再次检查是否有遗漏之处。
Image
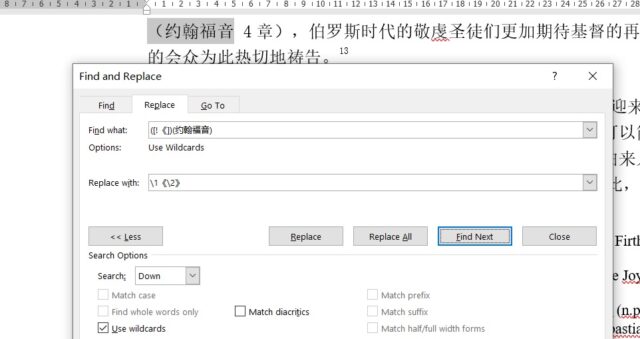
因为其中绝大多数都经过虹莹的修改,所以文本中同时存在如图的“(约翰福音 4章)”以及“《约翰福音》3:15”等不同的文字,有的需要修改,有的则不能再添加书名号了。
扁鹊先生曾经说过,疾在腠理,汤熨之所及也,但病在肠胃,就需要火齐之所及也。现在的状态,只能出动高级搜索替换功能了。
大抵而言,一个程序员的水平是否合格,端看他/她/它/ta的编译原理是否过关。如果知道正则文法,算是可以入门;如果可以写出有限状态机,大部分问题就不算难处理了。更高级的程序员可以弄明白编译器,而不会使用正则表达式和有限状态机的程序员基本上还没有入门计算机科学,只算是蔽林间窥之,偶尔跳踉大㘎而已。
微软的正则表达式功能很弱,被称为wildcards,中文翻译做“通配符”。不过正好够用,所以写了一个搜索串,“([!《])(约翰福音)”,以及一个替换串“\1《\2》”。
用圣经里66卷不同的书卷名字替换其中的“约翰福音”,大概又搜出了50处需要漏掉书名号的地方,简单地补充了上去。简单解释,方括号里的惊叹号表示“not”,所以**[!《]的意思是某个字符串前面有一个不是”《“**的字符。而圆括号则表示提前这个字符为一个子串。所以,整个表达式的意思是,寻找不带书名号的约翰福音,将其分解为两个子串,\1和\2,并在之间插入书名号。
现在有许多出版机构要求译者在翻译的时候将许多排版的格式甚至体例都修订好。这样的做法我是不赞成的。即使提高报价我也不愿意做这样的事情。
我在IT行业工作时只写Hello World!,提供算法,与客户沟通需求,不会去开发界面或写一个输入输出,因为我的时间价值不在简单的重复劳动,而在于创造性活动。
翻译的问题也一样。现在有很多时间花在格式,体例,甚至从PDF扫描提取英文,校对英文无误以后提供给译者上面。而一旦翻译完成,实际上我不太希望做这样的工作,所以动机很弱,拖延得厉害。
问题很显然,体例这样的工作,字体之类的事情,一个动正则表达式,掌握必要工具的编辑来处置会更好。
当然,整个神学翻译的状况,甚至整个神学出版业乃至于神学教育的状况都不佳,大概也没有什么好办法多请一个人来修订体例,最终实际上还是苛刻了译者的时间。
一叹!